대부분 LIKE를 '%'를 이용하여 검색을 많이 합니다.
쓰는데야 문제는 없겠지만 LIKE라는 걸 잘모르면 성능에 큰영향을 줄수 있습니다.
CUBRID demodb를 가지고 예를 들겠습니다.
우선 "create index game_idx on game(nation_code);"을 수행하여 nation_code의 인덱스를 생성합니다.
LIKE검색에서 인덱스가 타지 않는 경우
CUBRID Manager의 질의편집기를 이용하여 아래질의를 수행합니다.
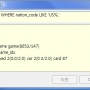
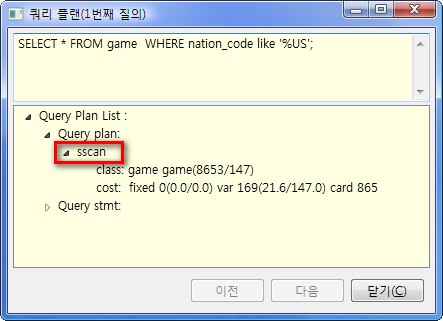
SELECT * FROM game WHERE nation_code like '%US%';
수행 후 Ctrl+l 을 누르면 질의 플랜에서 sscan(Sequence Scan)을 하고 있다는 것을 볼 수 있습니다.
즉, nation_code에 대하여 인덱스를 만들었지만 game테이블의 모든 nation_code에 대하여 'US'단어가 들어간 모든 데이터를 찾고 있습니다.
성능에 큰영항을 주겠죠?
결론적으로 LIKE연산을 할때 비교되는 대상의 앞에 '%"가 먼저 오면 INDEX를 사용할 수 없습니다.
너무 당연한 거지만 아래와 같이 '%'를 제거하여 INDEX-SCAN을 하는지 보겠습니다.
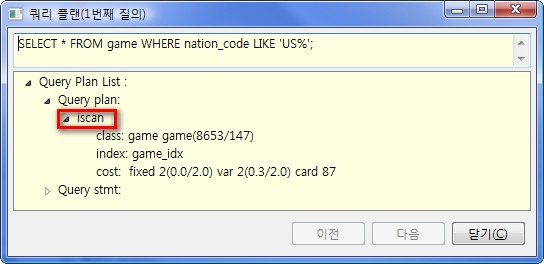
SELECT * FROM game WHERE nation_code LIKE 'US%';
수행 후 동일하게 Ctrl+l을 눌러 쿼리플랜을 보면, 아래와 같이 INDEX-SCAN을 하는 것을 알 수 있습니다.
여기서 좀더 고차원적인 문제가 생긴다면,
아마도 어쩔수 없이 '%XXX%'이런 형식을 써야 하는 경우일 것입니다.
예를 들어, USA혹은 US를 모르겠고 단지 중간에 S가 들어 가는 건 알고 있고 인덱스를 태우고 싶다고 한다면
편법(?)을 쓴다면 인덱스를 사용할 수 있도록 불필요한 조건을 부여하는 것입니다.
SELECT * FROM game WHERE nation_code >= '' and nation_code LIKE '%S%';
이 방법은 I-SCAN을 사용하는 예이므로 성능을 비교할 것이 못됩니다.;;
다만 복합적인 질의문 사용에 있어 보다 효율적으로 INDEX-SCAN을 하여 성능을 개선하고자 함입니다.
쓰는데야 문제는 없겠지만 LIKE라는 걸 잘모르면 성능에 큰영향을 줄수 있습니다.
CUBRID demodb를 가지고 예를 들겠습니다.
우선 "create index game_idx on game(nation_code);"을 수행하여 nation_code의 인덱스를 생성합니다.
LIKE검색에서 인덱스가 타지 않는 경우
CUBRID Manager의 질의편집기를 이용하여 아래질의를 수행합니다.
SELECT * FROM game WHERE nation_code like '%US%';
수행 후 Ctrl+l 을 누르면 질의 플랜에서 sscan(Sequence Scan)을 하고 있다는 것을 볼 수 있습니다.
즉, nation_code에 대하여 인덱스를 만들었지만 game테이블의 모든 nation_code에 대하여 'US'단어가 들어간 모든 데이터를 찾고 있습니다.
성능에 큰영항을 주겠죠?
결론적으로 LIKE연산을 할때 비교되는 대상의 앞에 '%"가 먼저 오면 INDEX를 사용할 수 없습니다.
너무 당연한 거지만 아래와 같이 '%'를 제거하여 INDEX-SCAN을 하는지 보겠습니다.
SELECT * FROM game WHERE nation_code LIKE 'US%';
수행 후 동일하게 Ctrl+l을 눌러 쿼리플랜을 보면, 아래와 같이 INDEX-SCAN을 하는 것을 알 수 있습니다.
여기서 좀더 고차원적인 문제가 생긴다면,
아마도 어쩔수 없이 '%XXX%'이런 형식을 써야 하는 경우일 것입니다.
예를 들어, USA혹은 US를 모르겠고 단지 중간에 S가 들어 가는 건 알고 있고 인덱스를 태우고 싶다고 한다면
편법(?)을 쓴다면 인덱스를 사용할 수 있도록 불필요한 조건을 부여하는 것입니다.
SELECT * FROM game WHERE nation_code >= '' and nation_code LIKE '%S%';
이 방법은 I-SCAN을 사용하는 예이므로 성능을 비교할 것이 못됩니다.;;
다만 복합적인 질의문 사용에 있어 보다 효율적으로 INDEX-SCAN을 하여 성능을 개선하고자 함입니다.
 Database(db이름) is running is standalone mode 오류가 뜰 경우
Database(db이름) is running is standalone mode 오류가 뜰 경우