
NEWS
-
Read More
DBeaver 환경을 새로운PC에 간편하게 복원하기
현재 Java로 구현된 데이터베이스 관리 툴 중에 가장 인기가 있는 툴이 DBeaver가 아닌가 생각된다. DBeaver 툴은 CUBRID 또한 지원을 해서 SQL Query browser의 기능을 충분히 수행한다. ※ DBeaver 특징 □ Community Edition 버전을 사용하면 라이센스(Apache License)가 무료이다. □ 자바/이클립스 기반으로 개발되어서 윈도우, 리눅스, MAC에서 구동된다. □ JDBC 기반으로 해서 DB를 지원한다. (CUBRID, ORACLE, SQL Server, MySQL, Postgresql ... ) □ 개발소스가 공개되어서 버그픽스가 가능하고 새로운 기능을 개발하여 사용이 가능하다. □ 릴리즈도 거의 2주마다 되기 때문에 버그 픽스또한 매우 빠른 편이다. CURBID를 DBeaver에서 사용하는 방법은 "DBeaver Database Tool 큐브리드 사용하기" 를 참조 하면 도움이 될 것이다. 필자는 해당 툴을 사용하다가 사용하는 PC를 바꾸게 되어 기존 설정을 백업해서 복구 하고자 한다. Workspace를 따로 빼서 사용하지 않은 기본 설정으로 사용하신 분을 기준으로 백업/복구를 가이드 하고자 한다. 순서는 다음과 같다. 1. 먼저 백업하고자 하는 기존의 환경에서 탐색기 창을 연다. 2. 주소/디렉터리 위치 표기창에 %appdata%... -
Read More
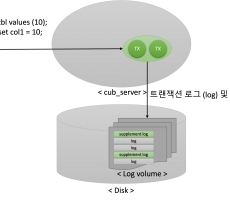
CUBRID Flashback
Introduction 큐브리드 11.2 버전이 릴리즈되면서 Flashback 기능도 함께 소개되었습니다. 아래에서는 큐브리드에서 제공하는 Flashback 에 대한 기능을 이해하기 위한 Background와 흐름, 그리고 사용방법에 대해 소개해드리겠습니다. Background Supplemental logging 사용자가 트랜잭션을 수행하면 트랜잭션 로그가 기록됩니다. 트랜잭션 로그에는 사용자가 변경하기 전의 데이터 (UNDO)와 사용자가 변경한 후의 데이터 (REDO)가 저장됩니다. Flashback에서는 별도의 전용 데이터 공간을 만들기 보다는 이미 로그 볼륨에 저장된 트랜잭션 로그를 사용합니다. 트랜잭션 로그의 UNDO와 REDO를 이용해 사용자가 수행한 SQL구문을 추측합니다. 하지만 트랜잭션 로그에는 데이터베이스의 물리적인 변경에 대한 데이터만을 가지고 있기 때문에, 논리적인 단위 (SQL 구문)으로 반환해야하는 Flashback을 위해서는 추가적인 데이터가 필요합니다. 추가적인 데이터에는 트랜잭션을 수행한 사용자 정보 등이 있으며, 해당 정보는 Supplemental log를 통해 저장됩니다. 따라서, Flashback을 수행하기 위해서는 ‘supplemental_log’ 시스템 파라미터를 1 또는 2로 설정해줘야... -
Read MoreNo Image
CUBRID to MySQL DBLink
CUBRID DBLink 란 데이터베이스에서 정보를 조회하다 보면 종종 외부 데이터베이스의 정보 조회가 필요한 경우가 있습니다. 이렇게 외부 데이터베이스의 정보를 조회하기 위해서 CUBRID DBLink를 이용하면 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다. 이 글에서는 CUBRID DBLink와 MySQL의 데이터베이스의 정보를 조회하는 방법을 가이드합니다. 적용 환경 OS 버전 : CentOS Linux 7 CUBRID 버전 : CUBRID 11.2.1 MySQL 버전 : MySQL 8.0 MySQL 서버 설정 설치되어 있는 MySQL 서버에서 해야하는 설정입니다. 1. MySQL SSL 설정 SQL 8.0 이상부터 ssl이 기본으로 설정되어 있어 설정을 끄고 실행합니다. 변경 후에는 MySQL을 재시작 해야합니다. 파일 위치: /etc/my.cnf ssl=0 ssl이 잘 적용이 되었는지 확인합니다. [root@localhost ~]# show variables like '%ssl%'; +----------+| Variable_name| Value |+-------------------------------------+----------+ | have_openssl | DISABLED | | have_ssl | DISABLED | 2. MySQL ... -
Read MoreNo Image
CUBRID to Oracle DBLink
CUBRID DBLink란 데이터베이스에서 정보를 조회하다 보면 종종 외부 데이터베이스의 정보 조회가 필요한 경우가 있습니다.이렇게 외부 데이터베이스의 정보를 조회하기 위해서 CUBRID DBLink를 이용하면 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다. 이 글에서는 CUBRID DBLink와 Oracle의 데이터베이스의 정보를 조회하는 방법을 가이드합니다. 적용 환경 OS 버전 : Centos7 Linux 7 CUBRID 버전 : CUBRID 11.2.1 Oracle 버전 : Oracle21.3.0.0.0 CUBRID DBLink 설정 다음은 CUBRID에서 Oracle DBLink를 위한 설정 방법입니다. 설정에 필요한 부분들은 다음과 같이 설정하였습니다. Oracle Server IP : 192.168.64.152 Oracle Server Port : 1521 Oracle SID : orcl Oracle 계정 : c##test Oracle 계정 암호 : test CUBRID Server IP : 192.168.64.153 CUBRID DB명 : demodb * Oracle 테이블 정보 create table code( s_name char(1), f_name varchar(6) ); 1. Oracle 설정 1-1) Oracle Client, ODBC Driver 설치 Oracle Instant Clien, ... -
Read More
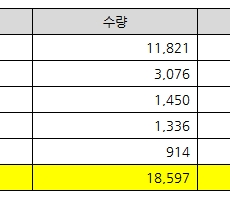
공공부문 DBMS 정보자원 현황
행정안전부/한국지능정보사회진흥원(NIA)에서는 매년 '범정부EA기반 공공부문 정보자원 현황 통계보고서'를 발간합니다. 2022년도 통계보고서는 금년 7월 초에 공개가 되었으며, 최근에 전자신문에서 통계보고서를 기반으로 한 스페셜리포트 기사(공공SW 외산 쏠림 해법은?)를 게재하였습니다. 전자신문 기사에서 공공SW 외산 쏠림 해법으로 2가지를 제시했습니다. 오픈소스 소프트웨어를 활용하여 외산 종속을 탈피하거나 공공부문 SaaS 국산화를 추진하자는 것입니다. 사실 국내 SW 산업은 정보보호, 관제 등 일부 분야를 제외하고 OS, DBMS, WEB/WAS, 백업 등 대부분의 영역에서 외산 편중이 높은 상황입니다. 이제부터 DBMS에 한정해서 조금 더 살펴보겠습니다. 아래 데이터는 2021년 기준이며, Oracle이 63.6%로 여전히 1위 자리를 지키고 있으며, 이어서 Microsoft (SQL Server), 큐브리드, 티맥스데이터(Tibero)가 순위를 차지하고 있습니다. [출처 : 2022년도 범정부EA기반 공공부문 정보자원 현황 통계보고서, 55쪽] 비록 Oracle와 Microsoft의 수량 점유율이 약 80%로 쏠림 현상이 강하게 나타나고 있으나, 큐브리드와 티맥스데이터의 수량을 합치면 15%가 ... -
Read More
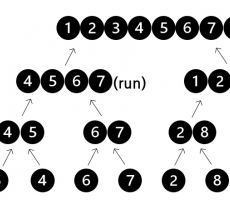
[CUBRID INSIDE] External Sort
External Sort DBMS는 다양한 상황에서 데이터를 정렬합니다. 사용자 요청으로 ORDER BY 절을 통해 정렬하기도 하고, UNION 절이나 DISTINCT 키워드가 사용되었을 때 중복데이터를 제거하기 위해 데이터를 정렬합니다. 그리고 sort merge join과 인덱스 생성시에도 데이터를 정렬합니다. 이렇듯 DBMS에서 정렬은 여러 상황에서 많이 사용되고 있습니다. CUBRID는 어떻게 데이터를 정렬하고 있을까요? external_sort.c 파일을 분석한 내용을 공유합니다. Merge Sort external sort의 기본이 되는 merge sort부터 살펴보겠습니다. merge sort는 데이터를 분할하고 합병을 반복하면서 정렬하는 알고리즘입니다. 정렬이 필요한 데이터를 분할하는데 분할된 조각을 run이라고 합니다. 분할이 완료되면 두 개의 run을 합병합니다. 위 그림은 분할 이후 합병하는 과정을 나타낸 것입니다. 합병을 진행하면 정렬된 새로운 run이 생성됩니다. 합병을 계속 진행하여 한 개의 run이 남을 때까지 반복하면 데이터 정렬이 완료됩니다. 그렇다면 두 run의 합병은 어떻게 진행이 될까요? depth 2의 두 run이 합병되는 과정을 살펴보겠습니다. 위 그림처럼 정렬이 진행됩니다. 두 run이 정렬되... -
Read More
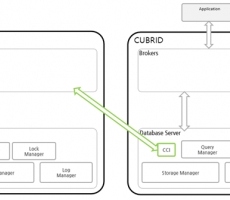
CUBRID DBLink
CUBRID DBLink 란 데이터베이스에서 정보를 주고받다 보면 종종 다른 타 데이터베이스의 정보 조회가 필요한 경우가 있다. 이렇게 타 데이터베이스의 정보를 조회할 수 있는 방법이 필요 하게 되었으며, CUBRID DBLink를 이용하면 타 데이터베이스의 정보를 사용할 수 있다. CUBRID DBLink는 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘한다. 단 타 데이터베이스를 여러 게 설정이 가능 하나, 정보를 조회할 때는 한개의 타 데이터베이스의 정보만 조회가 가능하다. 1. CUBRID DBLink 구성도 CUBRID DBLink는 동일기종 간에 DBLink 와 이기종 간의 DBLink를 지원한다. - 동일기종 간의 DBLink 구성도 동일기종의 타 데이터베이스의 정보를 조회하기 위한 구성도를 보면 Database Server에서 CCI를 이용하여 동일기종의 Brokers에 접속하여 타 데이터베이스의 정보를 조회할 수 있다. - 이기종 간의 DBLink 구성도 이기종의 타 데이터베이스의 정보를 조회하기 위한 구성도를 보면 GATEWAY를 통해서 이기종 타 데이터베이스의 정보를 조회할 수 ... -
Read More
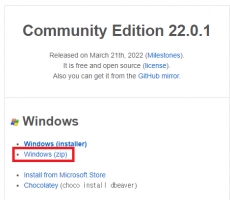
DBeaver Database Tool 큐브리드 사용하기 2
1. 들어가며 https://www.cubrid.com/index.php?mid=blog&page=2&document_srl=3827667 본문을 읽기 전에 위 링크의 글을 읽어보시는 것을 추천 드립니다. 2. CUBRID 사용 시 유의 사항 현재 DBeaver에서 CUBRID를 완벽하게 지원하고 있지 않기 때문에 사용할 수 없거나 누락된 기능이 존재합니다. 몇 가지 예시는 다음과 같습니다. Trigger, Sequence 정보 확인 불가 FK의 ON DELETE / ON UPDATE 옵션 수정 불가 column 생성 기능 사용시, Data Type, auto_increment, collation등 몇가지 기능 누락 및 사용 불가 뷰 테이블 생성, 수정 불가 JavaSP 확인 불가 Query Execute Plan 확인 불가 따라서 위에 기록된 기능을 사용해야 할 경우 Query를 직접 작성하여 사용하는 것이 권장됩니다. 2. DBeaver 설치 방법 위 글에서는 DBeaver를 installer를 통해 설치하는 것을 설명하고 있습니다. DBeaver는 Eclipse RCP 프로그램이기 때문에 installer를 사용하지 않고 설치할 수 있는 방법이 두가지가 더 있습니다. - zip을 활용한 portable 버전 설치 - Eclipse 내부의 plugin 방식을 통한 설치 * zip을 활용한 portable 버전 설치 이 글에서는 윈도우 기준으로 설명하고 ... -
Read More

[CUBRID INSIDE] 부질의와 QUERY REWRITER (view merging, subquery unnest)
- 부질의란? 질의가 질의안에서 다시 작성되는 것을 부질의라고 합니다. 이러한 부질의 덕분에 우리는 더 쉽게 하나의 질의로 원하는 데이터를 추출할 수 있습니다. 예를 들면 작년 평균 연봉보다 높은 직원을 추출해야 한다면 아래와 같이 부질의를 사용할 수 있습니다. 평균연봉을 구해서 다시 질의를 하지 않고 위와 같이 하나의 질의로 작성이 가능합니다. 너무 당연한 질의의 사용 방법이지만 사용이 불가했다면 많이 불편했겠죠. 이러한 부질의는 특별한 성질을 가지는 데 어느 부분에 작성되느냐에 따라서 가지는 성질이 달라집니다. - scalar subquery : SELECT 절의 부질의. 한 개의 데이터만 조회 가능. - inline view : FROM 절의 부질의. 여러 개의 데이터 조회 가능. - subquery : WHERE 절의 부질의. 연산자에 따라 scalar subquery 혹은 inline view의 성질. 부질의 사용은 질의를 더 다양하게 작성할 수 있도록 하지만 반대로 질의 성능에 악영향을 줄 수 있습니다. - 부질의 실행 순서와 성능 저하 원인 부질의는 주질의보다 항상 먼저 수행되어 임시 결과를 저장해놓습니다. 그리고 주질의가 수행되면서 부질의의 임시 저장된 데이터를 조회하여 원하는 결과... -
Read More
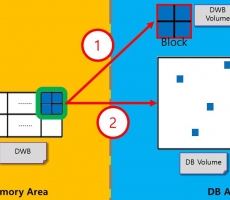
CUBRID Internal: 큐브리드 데이터의 디스크 저장 (Double Write Buffer)
들어가며 데이터베이스의 데이터는 디스크로부터 메모리에 할당되어서 읽힌 다음 수정을 하기도 하고, 새로이 생성되어 메모리에 할당되는 데이터가 있다. 이러한 데이터는 결과적으로는 디스크에 저장되어야 영구적으로 저장됨을 보장할 수 있다. 이 글에서는 큐브리드에서 데이터를 디스크에 저장하는 방법 중 하나를 소개하여서 큐브리드 제품에 대한 이해를 돕고자 한다. 현재 글을 쓰는 시점의 버전은 11.2이다. Double Write Buffer Double Write Buffer의 정의, 목적, 매커니즘을 거쳐 모듈에 대해 전반적인 설명을 하고자 한다. Double Write Buffer 란? 큐브리드는 기본적으로 Double Write Buffer를 통해서 디스크에 데이터를 저장한다. Double Write Buffer는 메모리와 디스크 양쪽에 구성되어 있는 버퍼영역이다. 기본적으로 2M의 크기로 설정되어 있으며, cubrid.conf 파일 내에서 그 크기를 32M까지 조절 할 수 있다. Note 큐브리드에서는 Double Write Buffer를 사용해서 DB페이지를 디스크에 저장하는 방법과 DB 페이지를 바로 디스크에 저장하는 방법이 있다. 이번 글에서는 Double Write Buffer를 사용해서 저장하는 방법만 언급하도록 하겠다. Double Write...