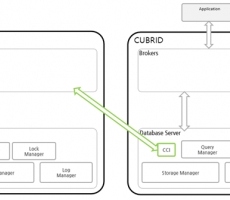
CUBRID DBLink 란
데이터베이스에서 정보를 조회하다 보면 종종 외부 데이터베이스의 정보 조회가 필요한 경우가 있습니다. 이렇게 외부 데이터베이스의 정보를 조회하기 위해서 CUBRID DBLink를 이용하면 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다.
이 글에서는 CUBRID DBLink와 MySQL의 데이터베이스의 정보를 조회하는 방법을 가이드합니다.
적용 환경
-
OS 버전 : CentOS Linux 7
-
CUBRID 버전 : CUBRID 11.2.1
- MySQL 버전 : MySQL 8.0
MySQL 서버 설정
설치되어 있는 MySQL 서버에서 해야하는 설정입니다.
1. MySQL SSL 설정
SQL 8.0 이상부터 ssl이 기본으로 설정되어 있어 설정을 끄고 실행합니다. 변경 후에는 MySQL을 재시작 해야합니다.
파일 위치: /etc/my.cnf
| ssl=0 |
ssl이 잘 적용이 되었는지 확인합니다.
|
[root@localhost ~]# show variables like '%ssl%'; +----------+| Variable_name| Value |+-------------------------------------+----------+ | have_openssl | DISABLED | | have_ssl | DISABLED | |
2. MySQL 패스워드 설정
MySQL 8.0부터는 default_authentication_plugin 이 “mysql_native_password”에서 “caching_sha2_password”로 변경되었습니다.따라서, 다음과 같은 에러가 발생이 됩니다.
|
ERROR: dblink - [HY000][2061] [unixODBC][MySQL][ODBC 8.0(a) Driver]Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection... |
이를 해결하기 위해선 MySQL 패스워드 정책을 변경이 필요한데 아래와 같은 3가지 방법이 있습니다.
- my.cnf 파일에 아래 구문을 추가합니다. 그 후 MySQL을 재시작한 뒤 새로운 계정을 생성하게 되면 자동으로 mysql_native_password 정책으로 변경됩니다.
...
default_authentication_plugin=mysql_native_password
... - 이미 생성된 user를 이용 시에는 아래와 같은 구문 이용해 plugin을 mysql_native_password으로 변경합니다.
ALTER user ' test'@'%' IDENTIFIED WITH mysql_native_password BY 'Mysql12!'; - 새로운 user(test)를 추가하여 사용 시 다음과 같은 구문을 이용해 정책을 명시합니다.
#구문
CREATE USER '{username}'@'{hostname}' IDENTIFIED BY '{passwordString}';
#예시CREATE USER 'test'@'%' IDENTIFIED WITH mysql_native_password BY 'Mysql12!';
* hostname : 사용자가 연결할 호스트, % : 모든 아이피 허용
다음 구문을 이용하여 해당 사용자의 host가 모든 IP(%)인지 또는 CUBRID IP인지 확인합니다. 또한 plugin이 “mysql_native_password”로 설정이 되어 있는지 확인합니다.
|
mysql> select user,host, plugin from mysql.user; | user | host | plugin | | test | % | mysql_native_password | .... |
3. 사용자 테이블 권한 설정
만약 사용자가 테이블 권한이 없을 시 설정이 필요합니다.
다음 구문을 통해서 모든 db 및 테이블에 권한을 주고 로컬 및 리모트에서도 접속 가능하도록 설정합니다.
|
#구문 GRANT ALL PRIVILEGES ON [데이터베이스명.테이블명] to [사용자@호스트] identified by '비밀번호' [with grant option];
GRANT ALL PRIVILEGES ON *.* TO 'test'@'%'; |
CUBRID DBLink 설정
다음은 CUBRID에서 MySQL DBLink를 위한 설정 방법입니다.
설정에 필요한 부분들은 다음과 같이 설정하였습니다.
- MySQL Server IP : 192.168.64.155
- MySQL Server Port : 56000
- MySQL DB명 : test_db
- MySQL 계정 : root
- MySQL 계정 암호 : Mysql12!
- CUBRID Server IP : 192.168.64.145
- CUBRID DB명 : demodb
MySQL테이블 정보
|
create table mysql_code( s_name char(1), f_name varchar(6) |
1. MySQL 설정
1.1) MySQL ODBC Driver 설치
MySQL ODBC Driver 다운로드 사이트:
-
링크를 통하여 OS 버전과 MySQL 버전에 맞는 파일을 다운로드하여 설치합니다.
https://dev.mysql.com/downloads/connector/odbc/[root@localhost ~]# yum install -y https://dev.mysql.com/get/Downloads/Connector-ODBC/8.0/mysql-connector-odbc-8.0.31-1.el7.x86_64.rpm
1.2) ODBC Driver Name 확인 및 설정
Linux의 경우, MySQL ODBC Driver Name을 설정하기 위해서는 unixODBC를 설치 한 후 /etc/odbcinit.ini 파일에 Driver name을 작성해야 합니다
unixODBC 드라이버 관리자는 Linux 및 UNIX 운영 체제에서 ODBC 드라이버 와 함께 사용할 수 있는 오픈 소스 ODBC 드라이버 관리자이다.
- unixODBC 설치 예시입니다. 버전에 맞는 ODBC를 설치를 진행합니다.
[root@localhost]$ yum install unixODBC.x86_64
설치 관련 자세한 내용은 http://www.unixodbc.org의 download를 참고 바랍니다.
-
unixODBC 설치 확인 및 odbcinst.ini 위치를 알 수 있다.
[root@localhost ~]# odbcinst -j
unixODBC 2.3.1
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /root/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
1.3) odbcinst.ini 설정
odbcinst.ini 에 MySQL 드라이버를 설정을 해주어야합니다. 다운로드 받은 드라이브 위치를 Driver에 입력합니다.
*CUBRID에서는 odbc.ini파일 설정이 필요 없음
|
# 세션의 이름이 driver 이름이다. # cubrid_gateway.conf의 CGW_LINK_ODBC_DRIVER_NAME 세션의 이름을 작성해야 한다.
[mysql odbc driver] |
2. CUBRID 설정
CUBRID gateway
게이트웨이는 CUBRID 데이터베이스 서버가 타 데이터베이스 서버에 연결할 수 있도록 중계하는 미들웨어이다.
cubrid_gateway.conf 설정
-
SERVICE 를 ON으로 변경
-
CGW_LINK_SERVER_IP 에 mysql database 서버의 ip주소 설정
-
CGW_LINK_SERVER_PORT 에 mysql database 서버의 port 설정
-
CGW_LINK_ODBC_DRIVER_NAME 에 odbcinst.ini에서 설정한 세션의 이름(mysql odbc driver)
*추가적인 GATEWAY 파라메터 설명은 메뉴얼을 참고해주시기 바랍니다.
https://www.cubrid.org/manual/ko/11.2/sql/dblink.html
|
[gateway]
[%mysql_gateway] |
cubrid_gateway.conf 확인
gateway 설정값을 확인 시 cubrid_gateway.conf 파일 열기 또는 cubrid gateway info 명령어를 통해 확인할 수 있습니다.
| [cubrid@localhost]$ cubrid gateway info
# gateway parameters were loaded from the files # gateway parameters [%mysql_gateway] SERVICE =ON APPL_SERVER =CAS_CGW MIN_NUM_APPL_SERVER =5 MAX_NUM_APPL_SERVER =40 APPL_SERVER_SHM_ID =56000 SSL =OFF APPL_SERVER_MAX_SIZE =256 SESSION_TIMEOUT =300 LOG_DIR =log/gateway/sql_log SLOW_LOG_DIR =log/gateway/sql_log/ ERROR_LOG_DIR =log/gateway/error_log LOG_BACKUP =OFF SOURCE_ENV = SQL_LOG =ALL SLOW_LOG =ON SQL_LOG_MAX_SIZE =10240 LONG_QUERY_TIME =60.00 LONG_TRANSACTION_TIME =60.00 AUTO_ADD_APPL_SERVER =ON JOB_QUEUE_SIZE =1024 TIME_TO_KILL =120 ACCESS_LOG =OFF ACCESS_LOG_MAX_SIZE =10240K ACCESS_LOG_DIR =log/gateway/ ACCESS_LIST = MAX_STRING_LENGTH =-1 KEEP_CONNECTION =AUTO STATEMENT_POOLING =ON CCI_PCONNECT =OFF ACCESS_MODE =RW CONNECT_ORDER =SEQ MAX_NUM_DELAYED_HOSTS_LOOKUP =-1 RECONNECT_TIME =600 REPLICA_ONLY =OFF TRIGGER_ACTION =ON MAX_QUERY_TIMEOUT =0 ENABLE_MONITOR_HANG =OFF ENABLE_MONITOR_SERVER =ON REJECTED_CLIENTS_COUNT =0 STRIPPED_COLUMN_NAME =ON CACHE_USER_INFO =OFF SQL_LOG2 =0 BROKER_PORT =56000 APPL_SERVER_NUM =5 APPL_SERVER_MAX_SIZE_HARD_LIMIT =1024 MAX_PREPARED_STMT_COUNT =2000 PREFERRED_HOSTS = JDBC_CACHE =OFF JDBC_CACHE_HINT_ONLY =OFF JDBC_CACHE_LIFE_TIME =1000 CCI_DEFAULT_AUTOCOMMIT =ON MONITOR_HANG_INTERVAL =60 HANG_TIMEOUT =60 REJECT_CLIENT_FLAG =ON CGW_LINK_SERVER =MYSQL CGW_LINK_SERVER_IP =192.168.64.155 CGW_LINK_SERVER_PORT =3306 CGW_LINK_ODBC_DRIVER_NAME =mysqltest CGW_LINK_CONNECT_URL_PROPERTY =charset=utf8;PREFETCH=100;NO_CACHE=1 |
gateway 상태 확인
cubrid gateway status 명령어를 통하여 현재 gateway 상태를 확인할 수 있습니다.
- cubrid gateway info 예시)
|
[cubrid@localhost]$ cubrid gateway status
@ cubrid gateway status % mysql_gateway |
CUBRID DBLink 사용 예시
1. MySQL 데이터 조회
타 데이터베이스의 데이터 조회를 위한 DBLINK Query문 작성 방법은 2가지이며 그 중 FROM절에 DBLINK 구문을 작성하여 데이터를 조회하는 방법입니다.
SELECT * FROM DBLINK ('CUBRID IP:CUBRID-GATEWAY-PORT:DBNAME:USER:PASSWORD:','SELECT select-list FROM remote_table') AS t(column-name column-type, …);
*MySQL DBLINK 실행 전 CUBRID gateway를 시작하여야 합니다.(cubrid gateway start)
다음 구문은 CUBRID에서 MySQL의 mysql_code 테이블 정보를 조회하는 예시입니다.
|
csql> SELECT * 'select s_name, f_name from mysql_code') AS M(s_name varchar(20), f_name varchar(20));
=== <Result of SELECT Command in Line 1> === s_name f_name ============================================ 'X' 'Mixed' 'W' 'Woman' 'M' 'Man' 'B' 'Bronze' 'S' 'Silver' 'G' 'Gold'
|
2. MySQL 서버 등록 후 데이터 조회
타 데이터베이스의 데이터 조회를 위한 DBLINK Query문 중 SERVER를 활용하여 데이터를 조회하는 방법입니다.
DBLINK Query를 작성할 때 마다 매번 작성해야 하는 번거로움과 사용자 정보(id, password) 가 외부로 노출될 우려가 있습니다.
이런 번거로움과 정보 보호를 위해 CREATE SERVER문을 이용하면, Query문 보다 간단하고, 사용자 정보 보호에 도움이 됩니다.
2.1) 서버 등록
CREATE SERVER문을 사용하여 원격 접속 정보를 생성합니다. 생성된 서버는 DBLINK를 이용하는 SELECT 질의를 수행 할 때 원격 서버를 지정하는데 사용합니다.
CREATE SERVER server-name(HOST,PORT,DBNAME,USER,PASSWORD,PROPERTIES,COMMENT);
*option: PASSWORD,PROPERTIES,COMMENT
다음 구문은 "remote_mysql"라는 이름으로 서버를 등록하는 예시입니다.
|
csql> CREATE SERVER remote_mysql ( HOST='192.168.64.145',
Execute OK. (0.032039 sec) Committed. (0.001417 sec)
|
2.2) 서버 등록 확인
다음 구문은 DB_SERVER 테이블에 서버가 등록된 것을 확인하는 예시입니다.
|
csql> SELECT * FROM DB_SERVER WHERE link_name='remote_mysql';
link_name host port db_name user_name properties owner comment ===================================================================================================================== 'remote_mysql' '192.168.64.145' 56000 'test_db' 'root' NULL 'PUBLIC' NULL
|
2.3) 서버 등록 후 데이터 조회
다음은 Create server 구문으로 만든 remote_mysql(서버명)을 조회하는 예시입니다.
SELECT * FROM DBLINK ('서버명','SELECT select-list FROM remote_table') AS t(column-name column-type, …);
|
csql> SELECT * FROM DBLINK (remote_mysql,'select s_name, f_name from mysql_code') AS M(s_name varchar(20), f_name varchar(20)); s_name f_name ============================================ 'X' 'Mixed' 'W' 'Woman' 'M' 'Man' 'B' 'Bronze' 'S' 'Silver' 'G' 'Gold'
|
3. MySQL VIEW 등록 및 조회
3.1) MySQL View 등록
mysql 데이터 조회 구문을 View로 생성하여 사용이가능합니다.
다음 구문은 CUBRID의 event 테이블과 MySQL의 mysql_code 테이블을 조인하여 View(test_view)로 등록하는 예시입니다.
|
csql> CREATE VIEW test_view as AS M(s_name varchar(20), f_name varchar(20)); |
3.2) MySQL View 등록 후 조회
다음 구문은 View(test_view) 등록 후 조회하는 예시입니다.
|
csql> select * from test_view; === <Result of SELECT Command in Line 1> === f_name s_name |
4. HA 환경에서 DBLink
HA 환경에서 절체되었을 경우 기존 슬레이브에서 mysql 연결을 위해 gateway 로 접속을 해야합니다. 일반적으로 gateway 는 CUBRID DB 서버상에 설정하는데, 절체되었을때 기존 마스트가 shutown 된 경우, 기존 마스터의 gateway 로는 접속이 불가능해지므로 MySQL db link 연결을 위해 접속할 gateway 는 슬레이브 상의 gateway 로 접속을 해야 합니다.
따라서 HA 환경에서는 master/slave 모두 동일하게 gateway 를 설정하여야 하며, DB link 를 위한 서버 설정시 gateway 서버의 주소를 localhost 로 해줘야, 절체후 자신의 서버의 gateway 를 통해 mysql 과 연결이 가능해집니다.
DBLink 시 사용하는 server는 master에서 등록 시 slave에도 복제가 됩니다.
| csql> CREATE SERVER ha_remote_mysql (HOST='localhost', PORT=56000, DBNAME=test_db, USER=root, PASSWORD='Mysql12!'); |
master와 slave는 동일하게 적용된것을 확인할 수 있습니다.
|
#Master DB_SERVER 테이블 결과 csql> SELECT * FROM DB_SERVER WHERE link_name='ha_remote_mysql';
=== <Result of SELECT Command in Line 1> === link_name host port db_name user_name properties owner comment
#Slave DB_SERVER 테이블 결과 csql> SELECT * FROM DB_SERVER WHERE link_name='ha_remote_mysql';
=== <Result of SELECT Command in Line 1> === link_name host port db_name user_name properties owner comment |
DBLink 사용 시 볼 수 있는 에러 메시지
-
ERROR: dblink - Cannot connect to CUBRID CAS
-
원인 : ip,port 정보 불일치
-
-
ERROR: dblink - Connection timed out
-
원인 : MySQL 미구동
-
-
ERROR: dblink - not supported type SQL_UNKNOWN_TYPE(0). [CAS INFO 192.168.64.145:56000,1,32448]
-
원인 : MySQL 버전 과 ODBC Driver 버전 불일치, 버전 동일 설정 후 정상동작
-
 CUBRID Flashback
CUBRID Flashback