
시작하며
이전 포스팅에서 CUBRID의 개발 문화: CUBRID DBMS는 어떻게 개발되고 있을까? 라는 주제로 블로그 글을 작성했었던 기억이 납니다. 날짜를 들여다보니 2021년 4월 29일에 작성되었으니 코로나 팬데믹을 이겨내고 CUBRID에서 여러 프로젝트를 진행하느라 시간이 훌쩍 지나갔네요. 그 사이 CUBRID는 11.2 (elderberry) 버전 릴리즈를 지나 11.3 (fig) 버전 릴리즈를 앞두고 있습니다.
이번에도 마찬가지로 [CUBRID의 개발 문화]라는 말머리를 가지고 CUBRID DBMS 프로젝트 빌드에 대한 이야기를 해보려고 합니다. 이전 포스팅의 ‘CUBRID DBMS는 어떻게 개발되고 있을까?’에서 소개했던 개발 프로세스와 프로젝트 기여 가이드의 내용과 조금 주제가 달라보일 수 있는데, 프로젝트 빌드에 대한 내용이 어떻게 개발 문화로까지 이어질 수 있는지 소개해 드리려고 합니다.
빌드 준비하기
누군가 코드를 기여하려고 할 때 빌드는 가장 먼저 해야 하는 첫 발걸음이면서, 동시에 제일 첫 번째로 마주하는 어려움입니다. 먼저 개발 환경에서 프로젝트를 빌드하기 위해서 여러 도구와 라이브러리를 설치하고, 프로젝트의 빌드 방법을 알아야 합니다. 이 때 기여하려는 개발자는 여러가지 어려움을 겪을 수 있습니다.
예를 들어:
- (1) 나의 개발 환경에서 빌드가 가능한지 모름
- (2) 필요한 개발 환경 (예를 들어 C++ 컴파일러), 라이브러리와 관련 도구를 어떤 것을 미리 설치해야 하는지 모름
- (3) 빌드 필요 요소 (Build Requirements) 의 최소/권장 버전과 설치 경로를 모름
- (4) 빌드 시스템/도구를 어떻게 사용하는지 모름
이러한 어려움에 대해서 물어보고 답을 받을 수 있는 커뮤니티 창구가 있으면 도움이 될 수도 있습니다. 하지만 대부분의 오픈소스 커뮤니티에서는 이러한 커뮤니티 창구가 없거나, 충분히 활성화 되어있지 않아서 답을 받아보지 못하거나 오랜 시간이 걸리게 됩니다. 많은 사람들이 이 단계에서 기여하기를 그만두게 될 것입니다.
빌드 준비를 도와주기
가이드 문서 작성하기
빌드를 시작해보기에 어려움을 겪을 수 있는 개발자를 도와주기 위해 빌드를 위한 가이드 문서를 코드와 함께 작성해야 합니다. 위의 ‘빌드 준비하기’ 에서의 어려움을 겪는 예를 기반으로 어떤 내용을 적어주면 좋을지 설명하면서 CUBRID 프로젝트의 사례를 소개합니다.
- 나의 개발 환경에서 빌드가 가능한지 모름: 프로젝트를 빌드 가능한 OS와 그 버전에 대해 명시해주는 것이 좋습니다. 만약 주기적으로 여러 OS 환경과 버전에서 빌드 테스트를 (Continous Testing) 수행하고 있다면 그것을 보여줌으로써 더 확실한 정보가 될 수 있을 것입니다.
- 필요한 개발 환경, 라이브러리와 관련 도구를 어떤 것을 미리 설치해야 하는지 모름: 기본적으로 C++ 컴파일러의 버전이나 자바 버전과 같은 지원하는 컴파일러와 함께 사용하는 라이브러리, 빌드 도구들을 어떤 걸 설치 해야하는지 알려주면 좋습니다. 만약 자동으로 설치된다면 어떤 것들이 설치될지도 알려준다면 혹시 이미 내 환경에 설치된 것과 충돌이 발생하지 않는지 확인할 수 있습니다. 아무런 정보 없이 빌드를 하면서 반복해서 빌드를 실패하고, 순식간에 지나가는 출력 속에서 에러를 찾아 헤매지 않도록 해야합니다.
- 빌드 필요 요소의 최소/권장 버전과 설치 경로를 모름: 특히 ‘yum’, ‘apt’와 같은 패키지 설치 도구에서 ‘yum install g++’, 또는 ‘apt-get install cmake’와 같이 명령을 입력했을 때 리눅스 배포판이나 그 버전에 따라 기본적으로 설치되는 버전이 다르므로 빌드가 가능한 명확한 버전을 알려주어야 합니다. 또 패키지 설치 도구를 통하지 않고 라이브러리르 직접 설치하거나 빌드해야 하는 경우에는 다운로드 받을 수 있는 경로를 적어주어야 합니다.
- 빌드 시스템/도구를 어떻게 사용하는지 모름: 프로젝트의 작성 언어나 플랫폼에 따라 다양한 빌드 도구를 사용할 수 있습니다. 자바 기반 프로젝트에서 사용하는 Ant, Maven, Gradle나 C/C++에서 Make, SCons, CMake, Ninja 등 다양한 빌드 시스템/도구가 있습니다. 이러한 빌드 시스템을 사용하여 작성한 스크립트를 처음부터 파악하기는 매우 어렵습니다. 같은 빌드 시스템을 사용하는 프로젝트라도, 빌드를 수행할 때 도구에게 넘겨주어야 하는 파라미터가 다르고 그 스크립트를 작성하는 컨벤션이 다를 수 있어 이해하지 못할 수 있습니다. 따라서 개발자가 기본적인 설정으로 쉽게 빌드해볼 수 있는 명령어나 스크립트를 제공해주어야 합니다.
CUBRID의 사례
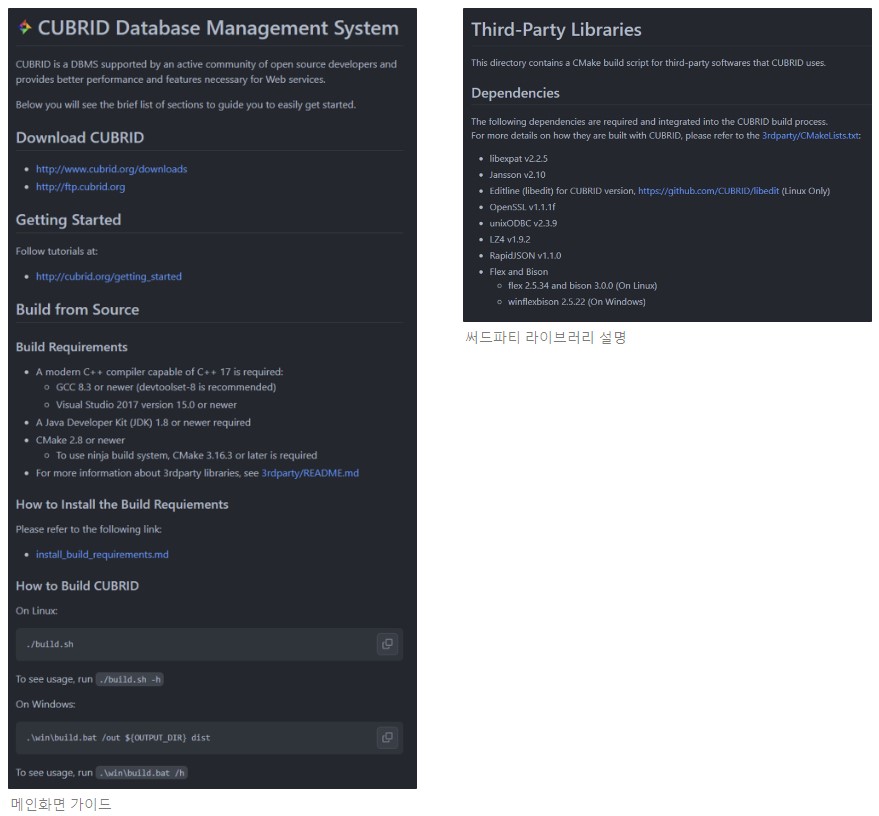
CUBRID의 경우에는 최근 fig에서 업데이트 된 README 파일에서 Linux 와 Windows 환경에서 빌드할 수 있음을 소스로 부터 빌드 가이드에서 알려주고 있습니다. CUBRID의 엔진은 주로 C++로 구현되어 있지만, 저장 루틴 기능은 Java를 사용하고 있어서 C++ 컴파일러와 JDK 버전에 대해 명시하고 있습니다.
빌드 시스템은 CMake를 사용하고 있습니다. CMake는 빌드 시스템에서 필요로 하는 파일을 유연하게 생성할 수 있는데, 그런 만큼 꽤나 어렵게 느낄 수 있습니다. 특히 빌드 도구에 넘겨줄 수 있는 여러 파라미터에 따라 디버그/릴리즈와 같이 다른 모드로 빌드할 수 있습니다. 이런 파라미터를 잘 지정할 수 있도록, 복잡한 빌드를 좀 더 쉽게 하기 위해서 CUBRID는 Linux에서 build.sh, Windows에서 build.bat을 제공하고 있습니다. 다음은 ./build.sh -h 명령어로 사용법을 출력한 예입니다.
|
Usage: ./build.sh [OPTIONS] [TARGET] TARGET EXAMPLES |
CUBRID에서 사용하는 대부분의 의존 라이브러리들은 빌드할 때 CMake에서 함께 자동으로 설치하고 빌드하고 있는데, 의존 라이브러리를 다루는 빌드 스크립트 (3rdparty/CMakeLists.txt) 와 함께 의존 라이브러리의 목록과 버전을 적은 README 파일을 함께 참고할 수 있도록 하고 있습니다. 또 미리 개발자의 환경에 설치되어야 하는 빌드 필수 요소들에 대해서는 각 OS 환경에서 설치할 수 있는 스크립트를 다음과 같이 적어주고 있습니다.
가이드 문서 개선하기
가이드 문서를 작성하는 것은 많은 노력이 필요하지만 빌드를 해보면서 겪을 수 있는 모든 문제를 완벽히 해결해줄 수 없습니다. 이제는 기여를 기대해볼 차례입니다. 위의 내용을 따라 작성한 가이드로 잘 안내했다면, 문제가 발생하는 부분은 보통 사소한 부분입니다. 예를 들어 시간이 지나면서 최신 버전의 리눅스 배포판 버전을 사용하는 개발자의 환경에 기본적으로 설치되는 라이브러리의 버전이 너무 높다라거나 라이브러리를 설치할 때 환경변수를 설정하지 않았다와 같은 것입니다. 이런 문제의 보고와 가이드 문서 개선은 오픈소스 기여의 좋은 출발점입니다.
따라서 개발자가 오픈소스 세상에 발자취를 남길 수 있도록 문서를 별도의 웹사이트에서 따로 관리하기 보다는 가이드 문서를 소스 코드와 똑같이 기여할 수 있게 해야 한다고 생각합니다. 그것은 개발자들이 오픈소스에 기여하려는 이유와도 같습니다.
가상 환경 제공하기
충분히 위의 내용과 같이 가이드 문서를 작성하더라도 개발자의 환경에서 이미 설치/설정된 라이브러리와 충돌 또는 잘못 설정된 환경 변수 등의 문제로 빌드 실패를 겪을 수 있습니다. 이 때 각 환경에 대해 트러블슈팅을 세세하게 제공해줄 수도 있지만 앞에서 설명한 것과 같이 아주 어려운 일입니다. 대신, 다음과 같은 도구를 이용하여 필요한 요소가 모두 갖추어진 가상 환경을 제공해주는 것도 하나의 방법입니다.
- Docker (https://www.docker.com/)
- Vagrant (https://www.vagrantup.com/)
CUBRID는 엔진 소스 코드의 높은 허들을 (복잡한 시스템에 대한 분석 비용) 낮추기 위해 오픈소스 커뮤니티에서 좀 더 모듈/프로젝트를 쉽게 기여할 수 있는 cubrid-contrib (https://github.com/CUBRID/cubrid-contrib) 저장소를 운영하고 있습니다. CUBRID는 @lsahn-gh (https://github.com/lsahn-gh) 님이 최근 기여한 ‘Sandbox’ 프로젝트를 통해 Docker 가상 환경에서 빌드/개발 환경을 제공하고 있습니다.
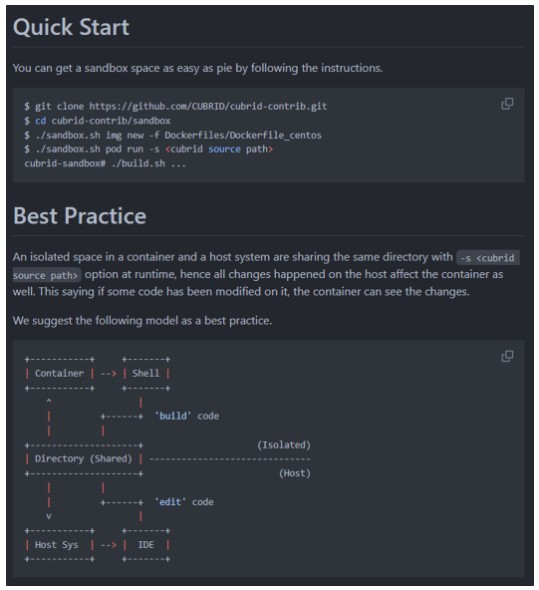
또 아직 CUBRID 저장소에 반영하지 않았지만, Vagrant 환경에서 각 CUBRID 버전을 빌드하는 위한 가상 환경과 그 가이드도 참고할 수 있습니다.
이제 빌드하고 개발해보자 그런데..?
이제 프로젝트에 기여하기 위한 첫 번째 산을 넘었습니다. 기여하기를 시작할 때 간단히 어떤 곳에 출력문을 추가해보거나 ‘프로그램을 죽여보는’ 코드를 집어넣은 뒤 빌드하고 실행해보면서 기능을 넣어볼 곳을 분석하기도 합니다.
이제 점점 프로젝트의 코드를 분석해서 알아가고 새로운 기능을 넣어봅니다. 이제는 소스 코드를 고쳐보고 빌드하고 테스트하는 것을 반복하는 (FIX - BUILD - TEST) 행복한 (?) 무한 루프 속에 자연스럽게 들어왔습니다.
이 때 프로젝트의 규모가 점점 더 커지다보면 한번의 루프를 반복하는 것도 꽤나 오랜 시간이 걸립니다. 예를 들어 겨우 코드 한줄 (!) 을 고쳐보고 테스트 하려고 하는데 거의 30분을 기다려야만 빌드가 완료됩니다. 이것은 점점 개발자의 생산성에 영향을 주기 시작합니다.
(농담을 하자면) 이제 30분 동안 문서도 작성해보고 방금 작성한 코드를 더 아름답게 바꿀 순 없을까 고민도 합니다. 그러다 이것을 반복하다보면 멍해지며 생각에 빠집니다. 아.. 최고의 복지는 제대로 일할 수 있게 해주는 것이라던데, 진행이 안되는구나. 역시 더 비싸고 좋은 장비를 사주었어야 하는걸까, 저 옆의 어디는 그거 준다던데...
아주 무서운(?) 농담이지만 개인적인 경험에 따르면 빌드 성능이 개발자가 기능을 개발할 때 집중력과 적극성에 분명한 영향을 준다는 것을 강조하려는 것입니다.
빌드 성능 개선하기
빌드 성능에 신경을 쓰는 것은 중요합니다. CUBRID와 같은 대규모 시스템의 경우에는 특히 빌드 시간이 꽤나 오래 걸립니다. CUBRID의 경우에는 Github의 Pull Request에서 매 commit 마다 빌드 테스트를 진행하므로 빌드 성능은 생산성에도, 비용에도 영향이 있습니다.
빌드 성능을 개선하는 많은 방법이 있겠지만 대표적으로 증분 빌드와 병렬 빌드를 잘 지원하는 것이 있습니다.
- 증분 빌드: 규모가 큰 프로젝트를 빌드 할 때, 이전에 빌드 되었지만 최신 상태인 것은 다시 빌드하지 않도록 하는 것
- 병렬 빌드: 빌드하면서 만들어지는 의존성과 오브젝트를 파악하여 병렬적으로 동시에 생성
이러한 방법은 빌드 시스템이나 도구에서 제공하지만 빌드 도구를 잘 선택하고 스크립트를 잘 작성해야 충분한 성능을 이끌어낼 수 있습니다. 빌드 성능을 개선하는 방법에 대해 설명하자면 너무 길어지므로 CUBRID가 개선한 사례로 설명하려고 합니다.
CUBRID는 Linux 환경에서 기본적으로 사용하고 있던 Make를 사용하고 있었는데, 빌드 성능을 저해하는 몇 가지 문제가 있었습니다.
- 빌드 스크립트의 버그: 의존 라이브러리에 대한 의존성이 제대로 설정되지 않아 병렬 빌드에 성능 저하가 발생
- Make는 너무 느리고 무겁다: Make 도구는 오랜 역사를 지닌 만큼 많은 것들을 고려하고 있어 비교적 빌드 속도가 느림
- 병렬 빌드를 위한 CPU 개수 확보: CUBRID는 Circle CI에서 빌드 테스트를 매 commit 마다 수행하는데 사용하는 Docker Containor의 CPU 개수가 적음
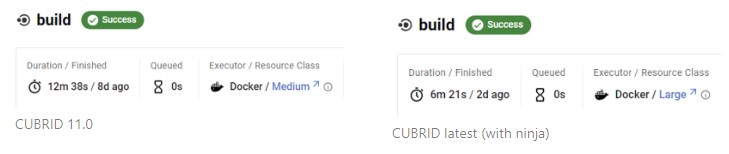
위의 문제를 기반해서 먼저 빌드 스크립트의 의존성을 제대로 설정하도록 수정하고, Circle CI에서 CPU를 2개만 제공하는 Medium을 Large로 변경했습니다. 또 Make보다 비교적 가볍고 빠른 Ninja 빌드 시스템으로 빌드할 수 있도록 도입했습니다.
다음의 결과로 보면 CUBRID 11.0 에서 12분이 걸리던 빌드 속도가 거의 절반인 6분으로 줄어든 것을 볼 수 있습니다.
CUBRID의 Windows 환경에서는 Appveyor에서 MSVC로 빌드하는데, 거의 30분 넘게 빌드를 기다려야 합니다. Appveyor는 오픈소스 커뮤니티 플랜의 경우에는 무조건 1 CPU로만 동작하기 때문에 병렬 빌드가 동작하지 않습니다. 따라서 충분한 자원을 확보해주고, 병렬 빌드가 작동하도록 개선했습니다.
개선 결과를 보면 Appveyor에서 거의 31분이 걸리던 빌드가 Circle CI에서 거의 13분 수준으로 향상된 것을 볼 수 있습니다.
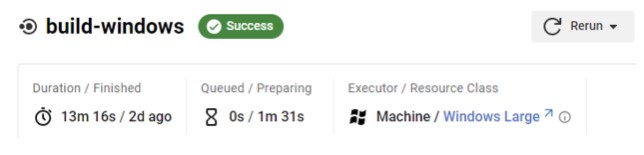
Circle CI에서 Linux (build → test)와 Windows 환경 (build-windows)에서 테스트를 보면, 거의 동시에 끝나는 것을 볼 수 있어 각 테스트 워크플로우가 끝날 때마다 함께 대응할 수 있습니다.
마무리
빌드에 대한 가이드는 프로젝트에 새로 합류하는 개발자의 좀 더 편안한 온보딩에 도움을 주고 그 비용을 줄여줍니다.
또 프로젝트에서 릴리즈 노트에 적히는, 눈에 보이는 기능 개발이나 성능 개선도 중요합니다. 그러나 어떻게 보면 눈에 보이지 않을 수 있는 빌드에 대한 개선은 개발자들이 코드를 작성하고 기여하는 활동 (코드 리뷰, 피드백에 대응하고 수정하는) 에 영향을 주어 프로젝트의 지속적인 발전의 윤활유가 될 것입니다.
참고
다음의 링크에서 위에서 소개한 빌드 가이드와 개선 사항에 대한 이슈를 참고할 수 있습니다.
- [1] 빌드 가이드 문서: http://jira.cubrid.org/browse/CBRD-21500
- [2] 병렬 빌드 버그 수정:
- [3] 의존성 라이브러리 개선:
- [3] Ninja 빌드 시스템 도입:
- [4] Windows 빌드 CI 개선:
 CUBRID QA 절차 및 업무 방식 소개
CUBRID QA 절차 및 업무 방식 소개







