
Materialized View
Materialized View(이하 MView) 이것은 말 그대로 View의 일종으로 일반 View는 논리적인 스키마인데 반해, MView는 물리적 스키마입니다. 논리적 스키마는 실제 데이터가 데이터베이스에 저장되어 있지 않고 데이터를 가져오기 위한 SQL질의만 저장되어 있다라는 것이고, 물리적 스키마 혹은 테이블이라는 것은 셀제 데이터가 데이터베이스에 저장되어 있다라는 것입니다.
MView는 필요한 결과를 가져오는 질의가 빈번하게 자주 사용 될 경우, 질의 실행 시간 속도 향상을 위해 데이터베이스 테이블을 만들어 저장해 두는 것으로 실행 비용이 많이 드는 조인이나, Aggregate Function을 미리 처리하여 필요할 때 테이블을 조회 하도록 하는 것 입니다. 예를 들면 대용량의 데이터를 COUNT, SUM, MIN, MAX, AVG 처럼 자주 사용되는 Aggregate Function 실행 속도를 향상을 위해서, 질의 실행 결과을 데이터베이스 테이블로 생성해 두는 벙법입니다. 즉, 자주사용되는 View의 결과를 데이터베이스에 저장해서 질의 실행 속도를 향상시키는 개념입니다.
이번 글에서는 일반적인 MView와 더불어 현재 작업 중인 데이터베이스 로컬 서버가 아닌 원격지(remote) 데이터베이스 서버의 테이블을 로컬 서버로 연결하는 것에 대한 내용으로, 일반적인 MView의 필요성에 더해 원격지 데이터를 가져오기 위한 효율성까지도 고려한 것으로 CUBRID에서는 아직 지원하지 않는 MView를 우회적으로 적용할 수 있는 팁이라고 할 수 있습니다.
MView의 특징
- MView를 만들어 둠으로써 질의 실행 시간을 줄일 수 있습니다.
- 응용프로그램에서 MView 사용 시 DBA는 응용에 영향을 주지 않고 생성하거나 수정/제거할 수 있습니다.
- MView는 대신 질의 실행 결과가 모두 저장되기 때문에, MView에 해당하는 테이블 만틈 공간을 차지하게 됩니다.
- 특히, 원격지 테이블의 경우 로컬 테이블에서 데이터를 가져오는 것보다 수 배의 시간이 소요될 수 있는데, 이를 로컬에 MView 테이블로 유지함으로써 성능을 최대한으로 끌어올릴 수 있습니다.
Oracle과 MView
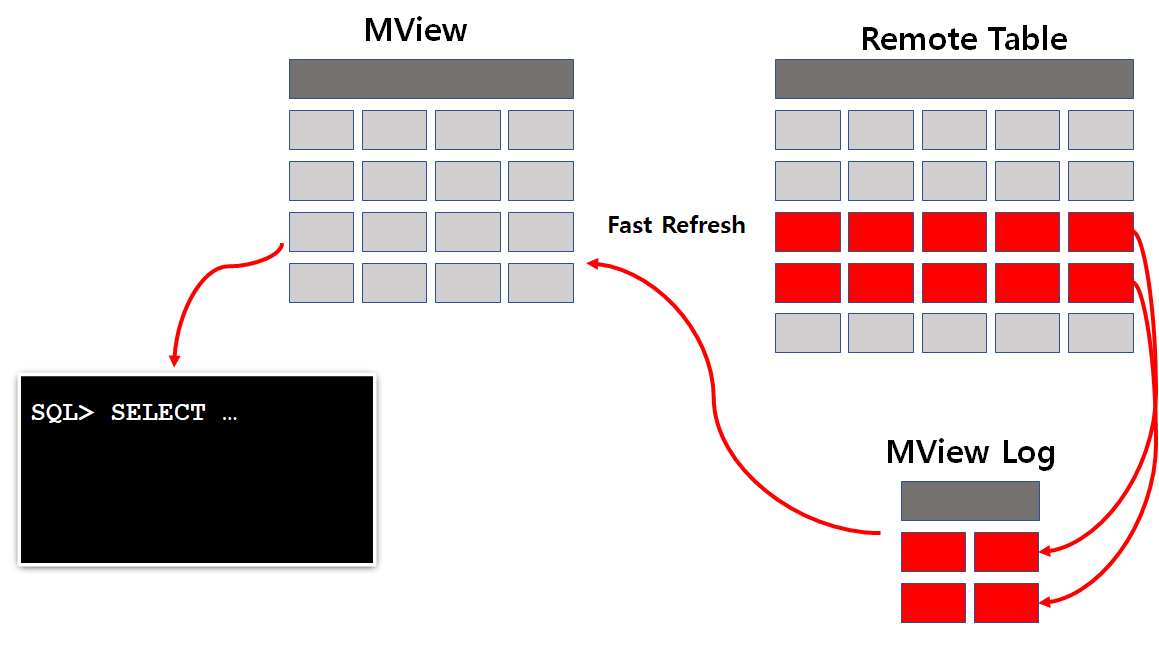
MView 또는 스냅샷이라고 하며, 로컬 또는 원격 테이블에 대한 질의를 기반으로 내용이 주기적으로 새로 고쳐지는 테이블 세그먼트입니다.
기본 문법은 아래와 같습니다.
|
-- Normal
-- Pre-Built |
문법을 잘 보면 MView가 어떻게 생성되고, 어떻게 동기화를 하는지에 대해 알 수 있습니다. 좀더 자세한 내용은 오라클 메뉴얼을 참조하시기 바랍니다. 동기화는 REFRESH와 ON절을 통해 연결된 테이블이 COMMIT될 때 혹은 요청이 올 때마다로 각각 동작이 됩니다.
CUBRID와 MView
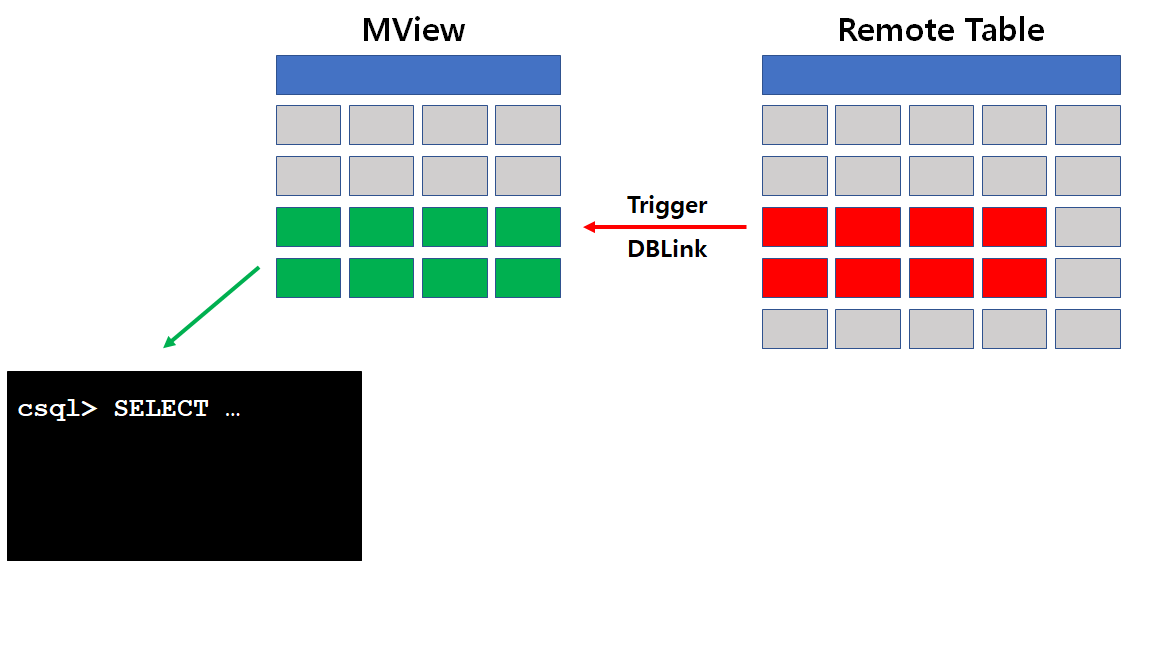
CUBRID는 아직 MView를 지원하지 않습니다. 그래서 MView와 유사한 효과를 만들기 위해서는 TRIGGER를 사용할 수 있습니다. 예를 들면 아래와 같이 update_logs라는 테이블에 데이터를 INSERT하는 것입니다.
|
CREATE TABLE update_logs(event_code INTEGER, score VARCHAR(10), dt DATETIME);
CREATE TRIGGER example |
로컬 서버의 데이터만 대상으로 하는 MView는 위와 같이 TRIGGER를 정의해서 테이블에 데이터를 INSERT하거나 UPDATE/DELETE할 수 있는데, 원격지 서버의 경우엔 아래와 같이 dblink를 활용할 수 있습니다.
|
CREATE TABLE remote_logs(event_code INTEGER, score VARCHAR(10), dt DATETIME);
CREATE SERVER remote_srv1 (
CREATE TABLE mview_trig(upd datetime); CREATE TRIGGER remote_exam
|
위의 예는 remote_logs라는 일종의 MView 역할을 하는 테이블에 원격지 history 테이블의 데이터를 INSERT하는 과정으로 정리할 수 있습니다. 트리거를 정의할 때, 원격지 테이블에서 가져올 수 있는 질의문은 조인이 포함된 복잡한 질의일 수도 있고, SUM이나 COUNT와 같이 Aggreate Function이 포함될 수도 있습니다.
 DBeaver 환경을 새로운PC에 간편하게 복원하기
DBeaver 환경을 새로운PC에 간편하게 복원하기







