
행정안전부/한국지능정보사회진흥원(NIA)에서는 매년 '범정부EA기반 공공부문 정보자원 현황 통계보고서'를 발간합니다. 2022년도 통계보고서는 금년 7월 초에 공개가 되었으며, 최근에 전자신문에서 통계보고서를 기반으로 한 스페셜리포트 기사(공공SW 외산 쏠림 해법은?)를 게재하였습니다.
전자신문 기사에서 공공SW 외산 쏠림 해법으로 2가지를 제시했습니다. 오픈소스 소프트웨어를 활용하여 외산 종속을 탈피하거나 공공부문 SaaS 국산화를 추진하자는 것입니다. 사실 국내 SW 산업은 정보보호, 관제 등 일부 분야를 제외하고 OS, DBMS, WEB/WAS, 백업 등 대부분의 영역에서 외산 편중이 높은 상황입니다.
이제부터 DBMS에 한정해서 조금 더 살펴보겠습니다.
아래 데이터는 2021년 기준이며, Oracle이 63.6%로 여전히 1위 자리를 지키고 있으며, 이어서 Microsoft (SQL Server), 큐브리드, 티맥스데이터(Tibero)가 순위를 차지하고 있습니다.
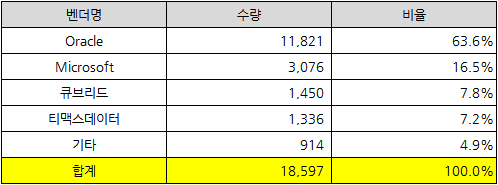
[출처 : 2022년도 범정부EA기반 공공부문 정보자원 현황 통계보고서, 55쪽]
비록 Oracle와 Microsoft의 수량 점유율이 약 80%로 쏠림 현상이 강하게 나타나고 있으나, 큐브리드와 티맥스데이터의 수량을 합치면 15%가 되며, 기타 항목에 들어가 있는 알티베이스 등 국내 벤더 수량까지 합치면 공공부문 점유율은 18.5%가 됩니다.
DBMS 제품 카테고리의 특성상 급격하게 시장 변화가 생기는 것을 아니지만 과거 국내 벤더들 전체 점유율이 10%도 안 되던 시절을 생각하면 그래도 점진적으로 개선이 되고 있다고 볼 수 있습니다. 특히, 최근 공공부문의 클라우드 전환 수요와 맞물려 오픈소스 또는 국산 DBMS의 수요가 계속 증가하고 있어서 향후 시장 개선에 대한 여지는 충분히 남아 있습니다.
앞으로 5년 후에는 시장 판도가 어떻게 변화해 있을까요? 큐브리드는 공공부문 DBMS 시장 3위 플레이어로서 오픈소스 기반의 제품 혁신 및 대고객 밀착지원을 통해 시장 변화의 선도자 역할에 최선을 다하겠습니다.
 [CUBRID INSIDE] External Sort
[CUBRID INSIDE] External Sort







